Description
The process migration framework (PMF) aims to extract a process from a shared system that hosts multiple processes, and redeploy it in a dedicated virtual machine. Moreover the PMF supports the documentation of the business process implementation. Main issues when migrating processes are the identification of the process environment (i.e. software packages, files, system settings) and the recreation of this environment. Existing migration tools mainly focus on complete systems or operate on a low level that is difficult to maintain. Main concepts of the PMF are the static and dynamic extractors for process information, monitoring of the process execution and the usage of a process context model to describe the process environment.
The main steps of this framework are described briefly below.
- Capture
Identification of the process environment. The source system is analyzed and the process environment represented as model. - Adapt
Refinement of the model. The model created in the previous step is adapted by e.g. replacing software. This step is optional, but adds the flexibility to handle changing re- quirements, like in tool versions. It is executed manually, supporting tools include Protégé and the Tool/Format Knowledgebase. - Build
Building of the target system. A virtual machine that corresponds to the refined model and where the process can be executed on is created. - Verification
Verification of the model and the target system. It is verified that the process on the target system shows the same behavior as the process on the source system. Also the model is verified for correctness and completeness. Supporting tools for this manual step include the Ontology Diff Tool and KDiff3.
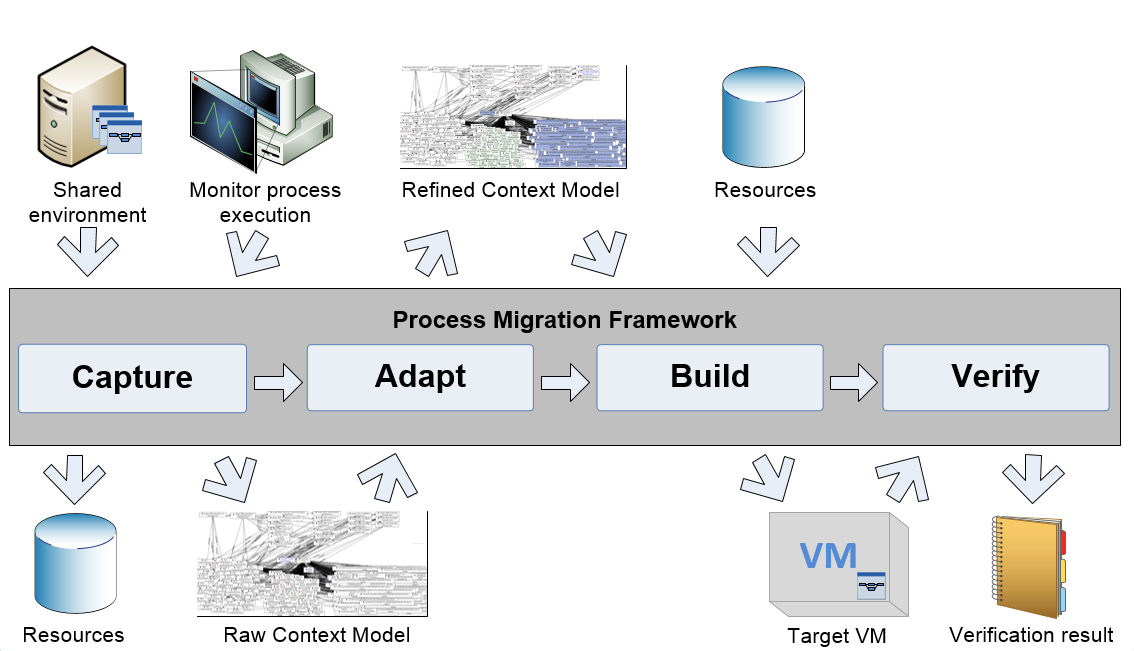
The resulting virtual machine is packaged as Vagrant box. The generated model is based on the TIMBUS context model and represented as OWL file. The basic structure of the model is shown in the following image.
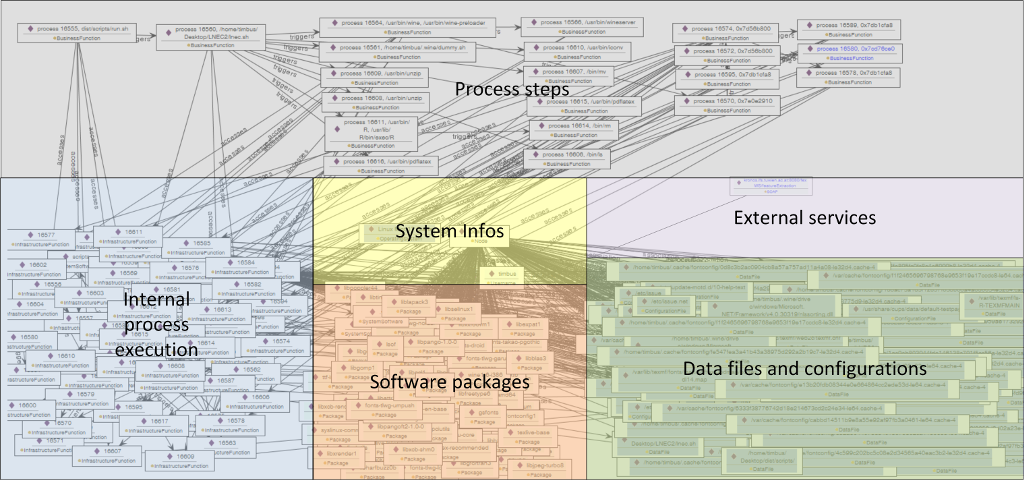
Examples
The exemplaric demo process which is shown below backups the index site of a web page. It uses wget to download the page and vim to mark it as backup. The resulting model as Ontology is shown below the demo process. To reproduce, run the capture module from within the "pmf_backup_web" directory of the tar-file, as described below.
Script that runs the demo process:
#!/bin/bash
out=dp_$(date +"%Y-%m-%d_%H-%M").html
outDir=data
url=http://ifs.tuwien.ac.at/dp/
postprocess=scripts/mark_as_backup
echo "----------------------------"
echo "PMF demo process: web backup"
echo " * download index page of $url"
echo " * mark it as backup"
echo " * move it to a backup dir"
echo "Requirements: vim, wget"
echo " install e.g. using 'apt-get install'"
echo "----------------------------"
echo ""
mkdir -p ${outDir}
wget -O ${out} ${url}
vim ${out} -c "source $postprocess | wq"
mv ${out} ${outDir}/${out}
Excerpt of the resulting process model:
...
<owl:NamedIndividual rdf:about="http://localhost/backup#local_system">
<rdf:type rdf:resource="http://timbus.teco.edu/ontologies/DIO.owl#Node"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fetc%2Fissue"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fetc%2Fissue.net"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fetc%2Flsb-release"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fhome%2Fuser%2F.viminfo"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fhome%2Fuser%2Fwork%2Fpmf_backup_web%2F"/>
<DIO:association rdf:resource="http://localhost/backup#%2Frun%2Fresolvconf%2Fresolv.conf"/>
<DIO:association rdf:resource="http://localhost/backup#%2Fusr%2Flib%2Flocale%2Flocale-archive"/>
<DIO:composedOf rdf:resource="http://localhost/backup#base-files"/>
<DIO:composedOf rdf:resource="http://localhost/backup#coreutils"/>
<DIO:composedOf rdf:resource="http://localhost/backup#graphviz"/>
<DIO:association rdf:resource="http://localhost/backup#user"/>
<DIO:composedOf rdf:resource="http://localhost/backup#klibc-utils"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libacl1"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libgpm2"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libidn11"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libnss-mdns"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libpcre3"/>
<DIO:composedOf rdf:resource="http://localhost/backup#libpython2.7"/>
<DIO:composedOf rdf:resource="http://localhost/backup#maven"/>
<DIO:composedOf rdf:resource="http://localhost/backup#ncurses-base"/>
<DIO:composedOf rdf:resource="http://localhost/backup#vim"/>
<DIO:composedOf rdf:resource="http://localhost/backup#vim-common"/>
<DIO:composedOf rdf:resource="http://localhost/backup#vim-runtime"/>
<DIO:composedOf rdf:resource="http://localhost/backup#vim-tiny"/>
<DIO:composedOf rdf:resource="http://localhost/backup#wget"/>
<DIO:composedOf rdf:resource="http://localhost/backup#zlib1g"/>
...
Download & Licensing
This tool is licensend under the Apache License Version 2.0. Show License Hide License
The PMF v0.4 beta is available for download.
The PMF v1.0 beta is available for download.
Requirements & Execution
The PMF consists of the capture and the build component, which can be called independently.
Runtime Dependencies
The PMF should work for most Linux distributions that use the Debian package management system. The capture component requires:- JRE 1.7
- strace
- dlocate
- debsums
- gawk
- apt-rdepends
- JRE 1.7
- VirtualBox 4.3
- Vagrant 1.6.3
Other versions of VirtualBox and Vagrant might work as well but have not been tested.
Usage
#!/bin/bash
executeworkflow.sh MusicClassification_WSDL.t2flow
sudo update-dlocatedb
java -jar capture-1.0-SNAPSHOT.jar ...
-a process execution script (mandatory), defaults to:
-d path to the data directory, defaults to: data/
-i input ontology path, defaults to:
-o resulting ontology path, defaults to: data/process.owl
-s capture script path, defaults to:
where the script that runs the process needs to be passed using -a. For the other arguments the default values can be used.
The repository of collected files, which is used by the build module, is stored to the "repo" directory inside the data directory by default. The resulting process environment model is stored as "process.owl" in the data directory by default.
For a custom blacklist of files, place "blacklist.txt" in the working directory and populate it with one filename each line. This allows to generally ignore files. For a custom blacklist of executables, place "blacklist_executables.txt" in the working directory and populate it with one filename each line. This allows ignoring files that are considered as executable when capturing sub-processes, i.e. for files in this blacklist no subprocess is added to the model. If a custom capture script is used mind that it produces the files and packages text files in the expected format (run with the default script (scripts/main.sh) to get an example). The default scripts packaged in the jar can be used as reference (scripts/*.sh).
For applying changes to the process environment model that has been created by the capture model an editor like Protégé can be used.
java -jar build-1.0-SNAPSHOT.jar ...
-i ontology path (mandatory), defaults to:
-r repository path, defaults to: data/repo
-b base machine URL, see http://www.vagrantbox.es/, defaults to:
http://files.vagrantup.com/lucid64.box
-m Vagrant manifest template path, usually not required, defaults
to:
-n virtual machine name, defaults to: vm
-o output path, for configuration data etc., defaults to: vbox
-p Puppet manifest template path, usually not required, defaults
to:
where the process environment model created by the capture module needs to be passed using -i. The other arguments are optional, but make sure to select a suitable base box, for which all the dependencies that the target systems requires are available in the official repositories. If this is not possible, manual adaption of the packages in the process environment model will be necessary. Base boxes can be found in http://www.vagrantbox.es/. If the build module is not started in the same directory as the capture module, the path to the repository where the artifacts of the source system are located can be specified using -r.
Custom Vagrant or Puppet templates can be created by extracting the default templates from the jar-file (templates/*.tpl) and modifying them. Customizing those files can be useful e.g. to specify a custom amount of memory that should be used for the virtual machine.
The resulting Vagrant package is stored as "package.box" in the "vbox" directory by default.
Further information
- Johannes Binder, Stephan Strodl, and Andreas Rauber. Process migration framework - virtualising and documenting business processes. In Workshop Proceedings of the 18th IEEE International EDOC Conference (EDOC'14), pages 95-103, Ulm, Germany, September 2014. [ bib ]
- Johannes Binder. Migration of processes from shared to dedicated systems. Master's Thesis, Vienna University of Technology, 2014. [ pdf | poster ]