Description
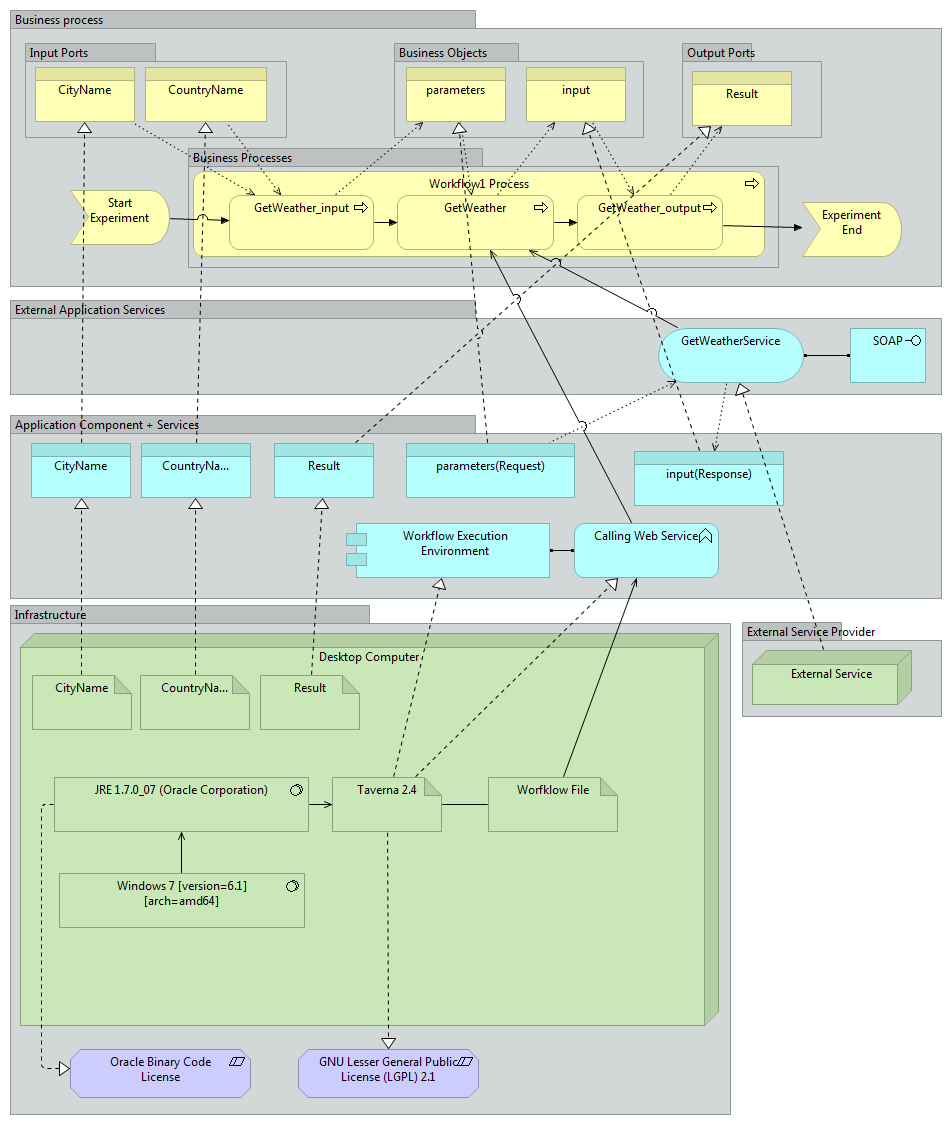
A Java command line tool which converts a Taverna workflow to an Archimate model instance. It creates a process model including the three Archimate layers Business, Application and Technology. Therefore, in a first step each Taverna processor gets presented as a Business Process element on the Archimate Business Layer. In addition, worklow input/output ports and intermediate values of process steps are modelled as Business Objects. For the various Taverna processor types (e.g., Beanshell Script, Tool Innvocation, External Services) we have defined transformation patterns to generate the Application and Technology layer elements. To extend the Archimate model with additional information on processed file formats (for a specfic workflow run), the converter accesses the Taverna provenance database to extract those files. In a further step DROID (Digital Record Object Identification) is used to identify the corresponding file formats defined in the PRONOM registry. This tool can also update an existing ontology with those gathered file format informations.
Example
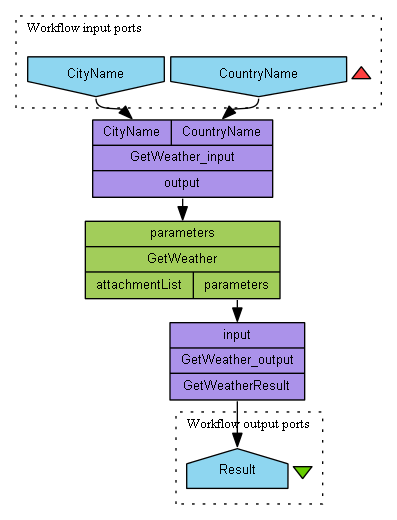
The left figure presents a simple Taverna 2.4 workflow, which uses a global weather web service to request the current weather information for a specific city. The automated converted Archimate model of this workflow is shown in the right figure.
Download & Licensing
This tool is licensend under the Apache License Version 2.0. Show License Hide License
The Taverna2Archi v1.0 command line tool is available for download.
This project is hosted at opensourceprojects. You can clone the project using following command:
git clone https://@opensourceprojects.eu/git/p/timbus/context-population/extractors/taverna-extractor timbus-context-population-extractors-taverna-extractor
In case you want to compile and build the program on your own, you can clone the from the link above and follow the instructions in the README file.
Requirements & Execution
Runtime Dependencies
- JRE 1.6+
- Maven 2+ (for the build process)
- DOT (comes with Graphviz)
- lib (include depedend libraries)
- droid-command-line-6.1.3.jar
- README.md
- TavernaExtractor.properties
- TavernaExtractor.jar
IMPORTANT: Before running the converter, you have to adapt the Taverna.properties file!
The extractor offers following commands:
A => -i,--inputFile...specifies the taverna t2flow (input) file. \path\to\taverna\input.t2flow -o,--outputFile ...specifies the archimate (output) file. \path\to\archimate\output.archimate -d,--dependencyDir ...workflow dependencies directory. [OPTIONAL] B1 => -d,--droid ...\path\where\to\save\droidOutputFile B2 => -cr,--report ...\path\where\droidOutputFile\is\located B3 => -ont,--ontology-file ...ontology to extend. \path\to\ontology -r,--reportFile ...generated DROID CSV report. -v, verbose ...enable verbose mode
In this section, we present a sample call for each command:
[A] Convert a Taverna Workflow to an Archimate Model:
java -jar TavernaExtractor.jar -i \path\to\TavernvaWorkflowInputFile.t2flow -o \path\to\ArchimateOutputFile.archimate
[B] Extract including file formats from Workflow and identify them with DROID.
In the following the 3 necessray steps are presented:
ATTENTION: Due to its DROID dependencies, make sure you are executing
the TavernaExtractor.jar in the respective directory!!
[B1] Running DROID identififaction on collected Taverna Workflow Run data:
INPUT: path to file which gets created.
OUTPUT: file containing DROID identification information in a none readable form.
java -jar TavernaExtractor.jar -d path\to\myDroidFile.droid
Sample Output:
===== [ID] | [Workflow Name (Timestamp)] ===== | 2 entries found.
[1] MusicClassificationExperiment (2013-09-25 13:11:42.488)
[2] MusicClassificationExperiment (2013-09-23 10:44:43.839)
Your choice: //Enter an ID to process
[B2] Generate a CSV report out of a DROID profile: (CSV report is stored in the same directory as the *.droid input file)
INPUT: file from step [B1].
OUTPUT: file in CSV format containing DROID information in a readable form.
java -jar TavernaExtractor.jar -cr path\to\myDroidFile.droid
[B3] Extend existing ontology with information about the used file formats in the workflow run:
INPUT1: existing OWL file, which should be extended.
INPUT2: file from step [B2].
OUTPUT: updates OWL file from INPUT1.
java -jar TavernaExtractor.jar -ont \path\to\myOntology.owl -r \path\to\myDroidCSVreportFile.droid.csv