The installation of the Combine-indexer was done with only minor complications. As it turned out, the robot was not tried for the operating system we use, and as a matter of consequence we were confronted with an incompatible module. However, only minor adaptations were necessary to make it work, which were implemented with the help of the fast support of the Combine-team at Lund University, Netlab28.
Subsequently, we incorporated archiving functionality in this tool, which was originally written for indexing purposes. Thereby, it was built on the experience of the Kulturarw3-project, which facilitated this task considerably.
Foremost, an archiving module had to be realised and integrated into the crawler. Its purpose is to enter the acquired documents into the repository, a functionality that is not necessary for the original tool, that barely stores specific information extracted from the harvested files that is of relevance for creating an index. In order to make the robot more efficient, we decided to turn off the indexing functionality completely.
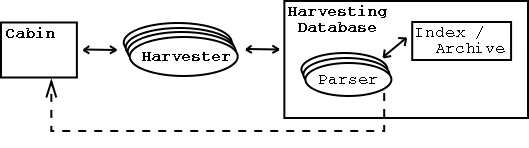
As it is shown in Figure 4.2, the Combine-program consists of three sub-packages. The so-called Cabin is the controller of the system. It contains lists of the URLs to be harvested, of those that have already been harvested. Following one of the available scheduling algorithms it assigns jobs to the Harvesters, namely URLs data is to be collected from.
Multiple instances of Harvesters are running at any time to increase the download rate. Having collected the files from the very location given by the Cabin, this material is handed to the Harvesting Database.
In the Harvesting Database the downloaded files are parsed with two goals. On the one hand, references to other documents are extracted. These URLs are subsequently handed to the Cabin, to register the documents for acquisition if they have not been harvested before.
On the other hand, the parser compiles the specific data that makes up the index, which is stored in a separate file for each URL, but also in an additional database. This part of the Harvesting Database was exchanged for the module building the archive, which stores the original data along with metadata in a specified hierarchy and format (cf. Section 2.3.3).
Besides this major reengineering, we implemented other adaptations in existing parts of the program. Some routines in the acquisition modules had to be reconstructed. Since an indexer is only interested in material it can actually understand and extract information from, it selects only those files for download it is able to parse. Using the tool for collecting on-line documents in a comprehensive manner, this limitation is not aspired. Similarly, identification of in-line pictures was added, based on the same principle as the corresponding functionality in the Nedlib-crawler, however, with a somewhat more elaborate list of file-extensions pictures could have that is extensible even while the robot is operating.
Also, of the information assembled in the communication with a web-server only items relevant for the indexing functionality were retained. Yet, this metadata is likely to represent a valuable source for statistical information concerning the overall structure of the Web. Thus, we constructed the archiving module such that this data is stored along with the original document. The file format as described in Section 2.3.3 was applied to guarantee a consistent collection.
During the active operation of the crawler we were confronted with parser processes that died again and again. This is due to erroneous HTML-code. Since average web-browsers have rather relaxed guidelines concerning the syntax and the accuracy of the HTML-code, users sometimes program their web-pages very slackly. Unable to anticipate all mistakes that can possibly be done, the parsers of the Combine-crawler face files they cannot interpret every now and then. Processes that have died when parsing, however, reduce the efficiency of the overall system significantly. Therefore, we refined a module that supervises those parsers, such that a process is automatically restarted if it did not produce useful output within a definable time-span.