The sheer masses of data to be stored in such an archive not only challenge the hardware, but they are also a strain on the operating system underneath. Limitations such as a maximum number of files in a directory and the maximum file size the operating system supports have to be accounted for. For this reason, the storage hierarchy has to be defined foremost. Apart from avoiding the systems limitations, a requirement is easy access to the data, i.e. a well-sorted archive. Another feature of the storage hierarchy would be storing files belonging to the same source, or - more specifically - belonging to the same web-server closely together. It can be expected that a user demanding a file in the archive will request other pages belonging to the same site. Grouping those files together accelerates access time in case slow storage media is used, since the requested files can be retrieved in a bulk.
For guaranteeing efficient operations of the archive a storage format has to be defined. It must incorporate stringent features for managing the collection items in the archive environment effectively, but it should be flexible enough for adaption in the future at the same time. Additionally, when archiving material from the Internet not only the original file needs to be stored, but also data about that very file. The so-called metadata includes, for example, indications on where and at what time the original file was retrieved. Alongside, metadata comprises specifications necessary for administering the file in the working environment, making it an integral part of the archive (for a closer discussion of metadata issues refer to Section 2.8). In principle, metadata could be kept external to the collection items in specific databases. Yet, for the sake of integrity, the original and its metadata should be kept closely together in the archive, or even as self-contained files holding both types of data [BK96]. However, parts of the metadata could be duplicated, for example in order to organise specified collection indices thereby improving on efficiency. Yet, any such additional data should be maintained as purely auxiliary and not as an integral part of the system.
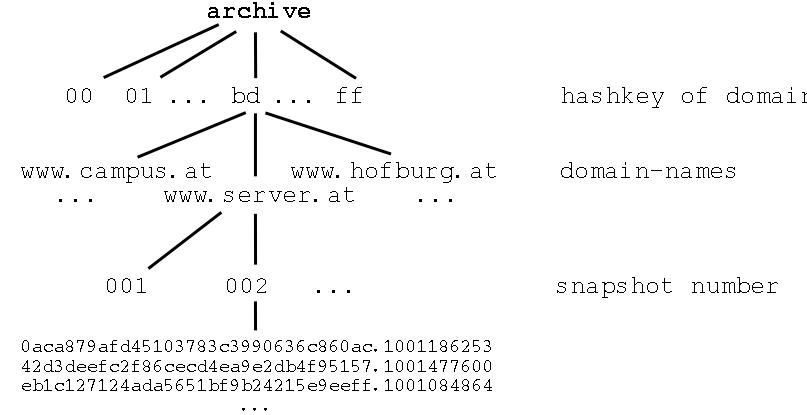
To make the requirements presented above more tangible the storage hierarchy used by Sweden's Kulturarw3-project is introduced in the following [MAP00] and sketched in Figure 2.2. This project acquires the data by making snapshots of the Internet, which is reflected in the storage hierarchy. It can be adapted easily, however, if changing to continuous retrieval.
Documents from the same web-server are grouped together. Before the name of the server, at the archive's top level, however, another partitioning layer is to be found, since well over 60.000 servers are accessed in a single run. To gain unique identifiers, a collision-proof checksum applying the RSA MD5 algorithm4 is used, that provides a unique sequence of 32 characters digesting any input. The first two characters of the MD5 checksum of the host-name is used at the top level in order to split the servers as uniformly as possible into 256 different directories. Next, the server-names are used as directory names. Following the IDs of already performed snapshots, a level further down the hierarchy, finally the files are to be found. The file name consists of a 32 characters long string, which is the MD5 checksum of the URL where the original data object was retrieved. Partitioned by a point, a time stamp is appended to this character string. Thus, a full path to a file retrieved from the web-server www.server.at in the second snapshot could look, e.g., like this: archive/bd/www.server.at/002/0aca879afd45103783c3990636c860ac.1001186253.
All information about a document is stored in one single self-contained file. This file is defined as a multi-part MIME (Multipurpose Internet Mail Extension) type and has three separate parts as displayed in Figure 2.3. The first part contains the metadata associated with the collection process, such as when it was collected. The second part contains the metadata delivered by the web-server. The actual content of the original file is to be found in the third part of the file. Not only additional fields holding meta information can be added to the first two parts in the future, also further parts can be added, if this turns out to be necessary in the future, making the file format very flexible.
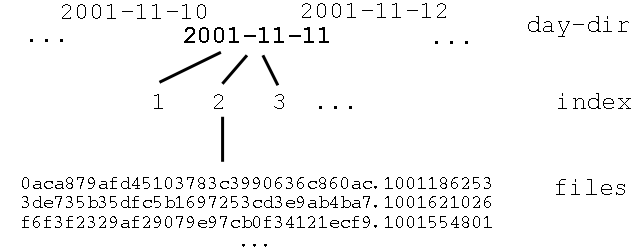
Another example is the format the Nedlib-crawler uses (cf. Figure 2.4). The data of the original document is not stored together with the metadata in self-contained files, yet, they are kept closely together. As in the previous approach, the MD5 checksum of the URL, where the data object was retrieved from, is taken as a filename for the original data. Additionally, a file with the extension *.meta is created, that contains the metadata. Those two files are stored together in a directory the name of which is simply a running number. After a certain number of files (by default 2.000) have been collected this index is increased and, consequently, the files are put into the new directory. Those directories with the running number are put into a higher level directory that is newly created each day the harvester is collecting files. However, files are not sorted according the web-server they belong to.
There are two ways when seeking a specific URL to find the corresponding file in the archive. Since this is not implicitly given by the structure of the storage, external information is necessary. Either a database needs to be consulted in order to find the number of the subdirectory the file is located in. Alternatively, files can be scanned that hold an identical copy of the metadata of any object in the repository together with the path where the object can be found. These files are called "accessX.data", where the 'X' is an index that is increased after a certain number of entries. Yet, scanning all those files takes time, hence, consulting the database is the more direct way to locate a collection item.
When defining how the data is stored, it should be considered, whether or not data in the archive should be compressed to reduce storage requirements and, subsequently, costs. Speaking against it is a certain loss in accessibility. Standard compression techniques should be chosen, and - obviously - lossy compression should be avoided, even for images [Dal99].