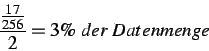An dieser Stelle wird nun auf den Speicherplatz und die angesprochenen Optimierungen eingegangen.
Ein Koeffizient aus dem Vektorfile ist eine reelle positive Zahl - der Hauptspeicherbedarf liegt somit bei 32 bit = 4 Byte, doch auf Festspeichermedien benötigt diese Zahl weit mehr.
Das Vektorfile ist ein Textfile, somit wird jedes Zeichen durch ein Byte dargestellt.
Die Zahl
![]() benötigt also 15 Byte Speicherplatz.
Um die Schätzung einfach zu halten wird der Speicherbedarf für einen Koeffizienten mit diesen 15 Byte beziffert.
Zusätzlich zu diesen 15 Byte kommt noch ein Trennzeichen (Leerzeichen) von der Länge eines Bytes.
Der Bedarf für eine Komponente eines Zeilenvektors liegt somit bei 16 Byte Speicherplatz auf dem Festspeichermedium.
Ohne die oben angenommene Berücksichtigung von nur 17 Frequenzbändern wäre die Anzahl der Koeffizienten 65535.
Somit läge der Speicherbedarf für einen Zeilenvektor bei (
benötigt also 15 Byte Speicherplatz.
Um die Schätzung einfach zu halten wird der Speicherbedarf für einen Koeffizienten mit diesen 15 Byte beziffert.
Zusätzlich zu diesen 15 Byte kommt noch ein Trennzeichen (Leerzeichen) von der Länge eines Bytes.
Der Bedarf für eine Komponente eines Zeilenvektors liegt somit bei 16 Byte Speicherplatz auf dem Festspeichermedium.
Ohne die oben angenommene Berücksichtigung von nur 17 Frequenzbändern wäre die Anzahl der Koeffizienten 65535.
Somit läge der Speicherbedarf für einen Zeilenvektor bei (
![]() ) 1 MB.
Ist die durchschnittliche Länge eines Liedes 4 Minuten 10 Sekunden, so liegt der Speicherbedarf für ein einziges Lied bei 50 MB.
Eine Liedsammlung mit nur 20 Liedern würde somit bereits ein Vektorfile von 1 GB füllen.
Rein vom Speicherplatz der heutigen Festspeichermedien (Festplatten mit über 50 GB Speicher gibt es heute schon im Einzelhandel zu kaufen) würde das keine unlösbaren Probleme darstellen.
Linux (Kernel 2.2) allerdings verhindert Dateigrößen über 2 GB
) 1 MB.
Ist die durchschnittliche Länge eines Liedes 4 Minuten 10 Sekunden, so liegt der Speicherbedarf für ein einziges Lied bei 50 MB.
Eine Liedsammlung mit nur 20 Liedern würde somit bereits ein Vektorfile von 1 GB füllen.
Rein vom Speicherplatz der heutigen Festspeichermedien (Festplatten mit über 50 GB Speicher gibt es heute schon im Einzelhandel zu kaufen) würde das keine unlösbaren Probleme darstellen.
Linux (Kernel 2.2) allerdings verhindert Dateigrößen über 2 GB![]() .
Die Laufzeit des SOM Programms würde auch beträchtlich sein.
Die hier verwendete Implementierung der SOM lädt außerdem das Vektorfile komplett in den Hauptspeicher.
Ohne die oben beschriebenen Optimierungen wäre die Implementierung zur Klassifikation einer großen Liedsammlung nach heutiger Sicht erschwert.
Durch die hier beschriebenen Optimierungen werden nur mehr etwa 3 % der ursprünglichen Datenmenge herangezogen.
Rechnung
.
Die Laufzeit des SOM Programms würde auch beträchtlich sein.
Die hier verwendete Implementierung der SOM lädt außerdem das Vektorfile komplett in den Hauptspeicher.
Ohne die oben beschriebenen Optimierungen wäre die Implementierung zur Klassifikation einer großen Liedsammlung nach heutiger Sicht erschwert.
Durch die hier beschriebenen Optimierungen werden nur mehr etwa 3 % der ursprünglichen Datenmenge herangezogen.
Rechnung ![]() zeigt noch mal, dass nur jedes zweite Segment, von 17 aus 256 ausgewählten Frequenzbereichen, betrachtet wird.
zeigt noch mal, dass nur jedes zweite Segment, von 17 aus 256 ausgewählten Frequenzbereichen, betrachtet wird.