Alle bisherigen Arbeiten enden hier und generieren direkt aus diesen Koeffizienten einen Eingabevektor. Kohonen selbst schlägt in seinem Buch vor, Fourierkoeffizienten als Merkmale zur Generierung von SOM Eingangsvektoren zu benutzen [#!kohonen!#]:
...one can use the elements of the ...Fourier amplitude-spectrum as features.Das erhaltene Frequenzspektrum (FRQ-Daten) stellt eine Momentaufnahme dar (engl: snapshot)und ist für die Klanganalyse geeignet. Um auf die Zeitachse zurückzukehren wird eine Gruppe von hintereinander liegenden Snapshots ausgewählt. In Experimenten stellte sich heraus, dass die besten Ergebnisse bei einer Snapshot Gruppe von insgesamt 5 Sekunden erzielt werden konnten.
Leider erweist sich die Entnahme einer fünfsekundigen Probe als schwierig, da der komplexe Aufbau von XMMS keine zeitlichen Schranken für die Berechnung erlaubt. Einerseits entstehen Timingprobleme durch die Plugin-Architektur, andererseits durch die Prozessorlast. Da Linux auch kein Echtzeitbetriebssystem ist, kann der XMMS Prozess auch von anderen Prozessen unterbrochen werden. Um exakte Zeitpunkte zu erhalten wird in das programmierte Plugin ein Timer eingebaut, der die real verstrichene Zeit zwischen zwei Sample-Arrays misst. Weiters wird durch die Auswahl einer sehr schnellen CPU und Beendigung aller nicht benötigten Programme dafür gesorgt, dass XMMS immer genügend Rechenzeit zur Verfügung steht. Die tatsächliche Prozessorlast lag bei den Experimenten während des Abspielens der Musik dauerhaft bei unter 10 Prozent. Die zeitlichen Probleme sind damit vorerst gelöst, doch bedarf es einer späteren Berücksichtigung der eingeführten Zeitstempel. Bei den Experimenten zeigte sich, dass XMMS etwa alle 20 ms ein Datenarray liefert. Für fünf Sekunden ergeben sich somit 250 Datenwerte.
Durch die am Computer gegebene Beschränkung des Speicherplatzes war allerdings noch eine weitere Optimierung notwendig. In Experimenten zeigte sich, dass es nicht nötig war jedes einzelne Frequenzband zu betrachten, sondern dass hier eine deutliche Datenreduktion wenig Auswirkungen auf die Ergebnisse hat. Daher wurden nicht alle 256 Frequenzbänder betrachtet, sondern nur jedes fünfzehnte, wodurch insgesamt 17 Bänder betrachtet werden (siehe auch Kapitel
Durch diese Zusammenfassung sind die Daten jetzt in Form einer im Ausdruck ![]() gezeigte zweidimensionale
gezeigte zweidimensionale ![]() - Datenreihe gegeben.
- Datenreihe gegeben.
Zur Anwendung kommt das Lagrange-Verfahren (Ausdruck ![]() ).
Bei diesem Verfahren hängen die Polynome nur von den Stützstellen
).
Bei diesem Verfahren hängen die Polynome nur von den Stützstellen ![]() ab (siehe Ausdruck
ab (siehe Ausdruck ![]() ).
).
Ergebnis der Interpolation sind 256 äquidistante Funktionswerte pro Funktion, an denen nachfolgend eine FFT durchgeführt wird.
Resultat sind 256 reale positive und negative Fourierkoeffizienten.
Aus diesem Zahlenfeld wird nun ein SOM Eingabevektor erstellt.
Da die SOM nur einstellige Vektoren akzeptiert, wird das zweidimensionale Feld in einen Zeilenvektor umgewandelt.
Noch einmal sei daran erinnernt, dass das hier gezeigte Verfahren nicht Melodie verarbeitend ist, sondern die Änderung bzw. Dynamik des Klanges untersucht.
Segmente, die in der Karte nebeneinander abgebildet sind, haben somit ähnliche klangliche Dynamik und nicht eine ähnliche Melodie.
Zur Illustration soll Abbildung ![]() dienen.
dienen.
Die Grafik zeigt drei fast gleiche fünfsekundige Musikstücke, die aus dem Refrain des Lieds Breathless (The Corrs)stammen.
Auf der horizontalen Achse sind die 256 Fourierkoeffizienten aufgetragen, und auf der vertikalen Achse deren Wert.
Stück ![]() beinhaltet ausschließlich Refrain.
Stück
beinhaltet ausschließlich Refrain.
Stück ![]() läuft Stück
läuft Stück ![]() um eine halbe Sekunde voraus und beinhaltet auch nur Refrain.
Stück
um eine halbe Sekunde voraus und beinhaltet auch nur Refrain.
Stück ![]() läuft Stück
läuft Stück ![]() um eine Sekunde voraus und beinhaltet sowohl Refrain, als auch einen kurzen Teil einer Strophe, die eine gänzlich andere Instrumentierung besitzt.
Abbildung
um eine Sekunde voraus und beinhaltet sowohl Refrain, als auch einen kurzen Teil einer Strophe, die eine gänzlich andere Instrumentierung besitzt.
Abbildung ![]() zeigt die Fourierkoeffizienten, die zur Vektorbildung für die Segmentkarte herangezogen werden.
Während Stück
zeigt die Fourierkoeffizienten, die zur Vektorbildung für die Segmentkarte herangezogen werden.
Während Stück ![]() und Stück
und Stück ![]() gleich klingen, da dieselbe Instrumentierung und derselbe Gesang vorherrscht, obwohl sie versetzt sind, zeigt Stück
gleich klingen, da dieselbe Instrumentierung und derselbe Gesang vorherrscht, obwohl sie versetzt sind, zeigt Stück ![]() ein gänzlich anderes Verhalten der Koeffizienten.
Dies zeigt eindeutig, dass das gezeigte Verfahren unabhängig von der Melodie nur auf die Dynamik des Klanges abzielt.
ein gänzlich anderes Verhalten der Koeffizienten.
Dies zeigt eindeutig, dass das gezeigte Verfahren unabhängig von der Melodie nur auf die Dynamik des Klanges abzielt.
In einem letzten Vorverarbeitungsschritt erfolgt eine Nullpunktverschiebung über den gesamten Bereich.
Da die Vektoren Kurvenbeschreibungen darstellen, muss man nur den kleinsten Koeffizienten über alle Vektoren wählen und dessen Absolutbetrag zu allen Koeffizienten dazuzählen um alle Kurven in den positiven Bereich zu übertragen.
Zum Schluss werden die Vektoren noch auf den Bereich ![]() Längen normiert.
Längen normiert.
![\includegraphics [width=0.6\textwidth,clip]{frq2}](img38.gif)
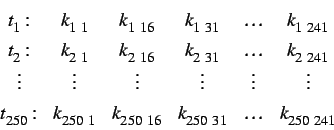
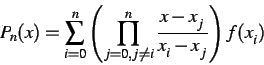
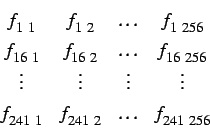
![\includegraphics [width=0.6\textwidth,clip]{frq3m}](img47.gif)
![\includegraphics [width=18mm,clip]{parsec}](img117.gif)