System¶
Abstract
On this page we describe the roles that interact with the infrastructure in great detail, introduce the general concepts used by the reference implementation, present the technical and social architecture and describe each core infrastructure component as well as the temporary VMs.
Overview¶
A secure system needs to deploy security controls that target every technical and organizational aspect specific to the setting of secured data visiting. We address the security of processing sensitive data by architectural design and automated decision making on behalf of stakeholders. The provider of the secure data infrastructure in legal terms acts as data processor, where the actual ingress of sensitive data is initiated by the Data Owner role (see Roles and Controlled Access for detailed role definitions) as is the egress (after initiation of the Analyst). Our secure data infrastructure stores the sensitive data in a central database that has a strict firewall barrier around it.
Only process-approved connections to selected VMs from Data Owner-VMs (for data import) or to Analyst-VMs once, on set-up, to provide an isolated copy of the data, as well as for maintenance and monitoring (Monitoring Node) are allowed to pass this barrier. The overall concept, in a nutshell, is centered around the principle of never providing access to the central Data Node where all data is being held. Instead, for each individual analysis request, the data required is extracted from the central Data Node and copied onto a dedicated node (Analyst-VM) together with the tools required to perform the analysis.
Access to this Analyst-VM is granted to the (single) Analyst working on the task at hand - however, never directly, but only via a dedicated Remote Desktop-VM to introduce a media break and avoid any data flowing off via e.g. a tunnel. Thus, an Analyst can establish a remote desktop connection to a dedicated VM from which he or she has the sole possibility of establishing a secure shell connection (SSH) to the corresponding Analyst-VM, holding a copy of only the subset of data (possibly finger-printed and aggregated) as well as the tools required for addressing the task at hand. Export of any result files such as trained models, figures, charts is again possible only via a dedicated Data Owner-VM to ensure approval of Data Owner. These VMs are being destroyed after a specific transfer or analysis task has been completed.
Controls¶
To prevent data leakage, our approach implements multiple layers that secure the control of the data from the physical location of the server to the pixel displayed on the screen in five controls. Since analysts need to disclose how they are going to use the data through an approval process, the data owner may have interest in checking for the truthfulness of their statement.
Data Segmentation¶
To achieve a clear segmentation of data streams for different roles, we implement a control that provides strongly restricted, isolated virtual machines for any entity external to the organization. We provide a central Data Server that enables precise data identification and citation by implementing the recommendations on dynamic data citation of Rauber et al., 2021.
For Analyst-VMs that are used by the Analyst role, additional policies are implemented in the secure data infrastructure. To retain all control on the VM, access is only allowed through Remote Desktop-VMs protected by a secure connection in offered by the VPN Node that only allows traffic to a single Analyst-VMs.
This massive overhead of processes running in own VMs only allows for visual access to the data. An adversary still is able to take screenshots of e.g. paginated views of data or using code to display encoded representation of data in matrix barcodes. By having a copy of all code being deployed on VM set-up and recording both the Remote Desktop-VM data stream as well as VM activities on the Monitoring Node allows tracing of such activities to detect unusual behaviour in task processing.
Network Segmentation¶
Following current best-practices, we separated the Data Node from the Data Owner- and Analyst-VMs by placing them into their own network subnets as additional security control of our method.
The standard netfilter module of the Linux kernel is sufficient for our purposes and is used on the Gate Node and the VPN Node. In the reference implementation, we use the firewall daemon shipped with Rocky Linux. OpenStack takes care of the subnets in general and managing traffic that passes the virtual bridges of the subnets. The set-up configures the security groups and rules in an automated way to allow only the ports of the services installed and may restrict the audience by IP, i.e. TCP port 22 (SSH) for the VPN Node is allowed only from within the TU Wien subnet. It uses the netfilter module to restrict the traffic passing the subnets including to specific Data Owner- and Analyst-VMs to make them visible only for the authenticated role. Furthermore, the VPN Node uses the netfilter module to restrict all traffic that is not point- to-point protocol.
Network connections between VMs and the open Internet are prohibited using the low-level netfilter kernel module. To not expose the secure data infrastructure to unpatched security vulnerabilities, read access capabilities to package servers and manually configured license servers are allowed. To make administration straightforward and as failsafe as possible with the tools present, we have a VPN Node that runs an implementation of OpenVPN Access Server through a popular set-up script.
We want the Analyst role to know as little as possible about the secure data infrastructure, therefore the netfilter module in the VPN Node is configured to only allow connections to the one single IP of the Remote Desktop-VM that the Analyst role is provided with. Note that contrary to the Data Owner-VM, a Analyst-VM does not allow direct external secure shell interaction. For Analyst-VMs the Analyst role first connects to the assigned Remote Desktop-VM which enables secure shell interaction with the respective Analyst-VM.
Automation¶
An automation engine like Ansible allows infrastructure operators to control how repetitive processes are executed on the system by using configuration files and scripts. Capabilities to install, configure, update and uninstall parts of the system are supported by the engine and provide a valuable tool to administrators that can customize the system by changing e.g. environment variables only. We use the infrastructure-as-code capability of Ansible to operate the infrastructure and allow any organization to add or remove components as they see fit.
We only select best-practice open-source software which at the same time limits the reference implementation when i.e. managing identities and configure one jinja template per instance for cloud init. Cloud init allows to configure the nodes when creating them non-interactively with a simple yaml-like template.
roles/setup_node/templates/identity.cfg.j2:
#cloud-config
hostname: ossdipidentity
timezone: {{ timezone }}
package_update: true
package_upgrade: true
users:
- name: sysadmin
sudo: ALL=(ALL) NOPASSWD:ALL
groups: wheel,docker
lock_passwd: true
ssh_authorized_keys:
- {{ lookup('file', sysadmin_pubkey) }}
power_state:
mode: poweroff
message: Installation finished, shutdown.
condition: cloud-init status | grep "done"
packages:
- firewalld
- vim
...
runcmd:
- /root/rsyslog-init && logger "Configured rsyslog"
- /root/firewall-init && logger "Configured firewalld"
...
write_files:
- path: /root/rsyslog-init
permissions: '0744'
content: |
#!/bin/bash
logger "Configuring rsyslog ..."
echo 'action(type="omfwd" Target="172.27.48.7" Port="514" Protocol="udp")' >> /etc/rsyslog.conf
/bin/systemctl enable rsyslog
/bin/systemctl start rsyslog
- path: /root/firewall-init
permissions: '0744'
content: |
#!/bin/bash
logger "Configuring firewalld ..."
/bin/firewall-offline-cmd --add-service={ntp,dns,freeipa-4,syslog}
/bin/firewall-offline-cmd --list-all
/bin/systemctl enable firewalld
/bin/systemctl start firewalld
...
For example, we use FreeIPA that integrates with RHEL-based operating systems and uses Kerberos and OpenLDAP. It creates a standalone server with integrated DNS that also creates on set-up:
- User groups: sysadmins, dbadmins, owners, analysts, providers
- User accounts: sysadmin, dbadmin
- Host groups: corenodes, datanodes, ownernodes, analystnodes, desktopnodes
- HBAC rules: allow_sysadmin, allow_dbadmin
Corporate identity management
Many modern organizations use commercial identity management systems such as (Azure) Active Directory that holds the
organization's policies to manage access to resources. The Identity Node can easily be replaced with commercial
software. In this case you will need to modify the template located in roles/setup_node/templates/identity.cfg.j2
to fit your identity management service.
Monitoring¶
Every operation performed on the isolated Data Owner- and Analyst-VMs is monitored closely using explicit contractual agreements between the respective role and the Data Owner. The Monitoring Node is configured to only append to log files and does not allow modifications by the System Administrator. We noticed early on, that only system-level logging alone is not sufficient for later investigation. Although VMs are able to send the events to the central Monitoring Node within the secure data infrastructure, it does not provide enough information to comprehend the performed operations since it only captures the infrastructure’s actions.
In the reference implementation, all logs of the nodes inside the VPN-, VNC-, Provider-, Analyst- and Owner network are sent to the Monitoring Node that is connected to these networks.
Roles and Controlled Access¶
Data Owner¶
The Data Owner has a strong interest in providing an untrusted expert access to the data but wants to retain control of the data and specifically reduce the risk of data leakage to an acceptable level.
Our approach provides temporary and isolated Data Owner-VMs that allow import of structured data to the database of the Data Server after which it is destroyed and consigning the Data Owner full control over who the data is provided to.
It furthermore has access to comprehensive logging information providing a full audit trail of all interactions with their data within the infrastructure from data import, via any provisioning steps to data deletion at the Logging Server.
Analyst¶
Analyst has a clear understanding on what data is required and what research questions need to be answered with it. This role can be assigned to experts that need to analyze or process the data, but where sharing the data is not feasible.
With the permission of the Data Owner, the Analyst role is able to use an according subset of the data in isolated VMs that have compute-optimized hardware configurations.
Access is only granted for a limited time period with the possibility to extend it following request and approval processes via the Data Owner. The Analyst role is granted access only to their corresponding Analyst-VMs (via Remote Desktop-VMs) created explicitly for the approved set of analysis or processing goals. It is therefore possible for the Analyst role to have access to more than one VM depending on the number of independent tasks.
Data Provider¶
The Data Provider is processing the data on behalf of the Data Owner. He or she manages the services and takes care of all operations of creating the respective isolated VMs for Data Owner- and Analyst roles, monitors user interactions, and handles the legal contracts required.
It may outsource the actual hardware provisioning to a sub-contracted Carrier role, although frequently these two roles will be combined to reduce complexity and risks. In many cases, the Data Owner may itself decide to provide the services, leading to a simpler set-up and accordingly simpler processes for data ingress by combining the Data Owner- and Data Provider roles.
Carrier¶
The Carrier is the organization that operates the secure data infrastructure. Our approach allows for the Data Provider roles to decide where the infrastructure is going to be hosted.
Although we highly recommend to host it on-premise in the immediate physical control of the Data Provider, it can be deployed on a third party private cloud provider acting as a Carrier. However, the possibility of a backdoor may outweigh the benefits of predictable infrastructure costs and automated backups among others for small organizations.
Database Administrator¶
The Database Administrator is a role that is responsible for maintaining the central Data Server and the PostgreSQL database running on it. The Database Administrator role is nominated by the provider organization and is mutually exclusive with the System Administrator role. This exclusivity is required to not enable a change in the central Data Server and subsequently manipulate the logs in the Logging Server.
With the introduction of zero-knowledge databases, this role can be made obsolete since the provider organization or Database Administrator cannot access the database anymore. This role also has to maintain the Key Servers that store the compound passphrase for decrypting the encryption key for the VM disks.
System Administrator¶
The System Administrator maintains the secure data infrastructure environment, except for the central Data Server. This role also manages the platform where the infrastructure is hosted.
Architecture¶
Technical Measures¶
A virtual machine is orchestrated by a hypervisor (or "virtual machine monitor"), which has to be installed on the host either directly or on top of another operating system. The hypervisor isolates VMs from each other at all times. In our case, we want to extend this isolation to a degree that artificially air-gaps each VM where only the responsible role and the secure data infrastructure itself can operate the machine within a limited boundary.
Nodes and Virtual Machines
We refer to nodes as general term for both physical and virtual machines. They can be either one. When using the term virtual machines, we mean a virtualized computing unit.
However, this task is not trivial since not all approaches are equal in effectiveness. For example, the remote frame buffer protocol allows to remotely control another machine by transmitting controlling signals like mouse- and keyboard events.
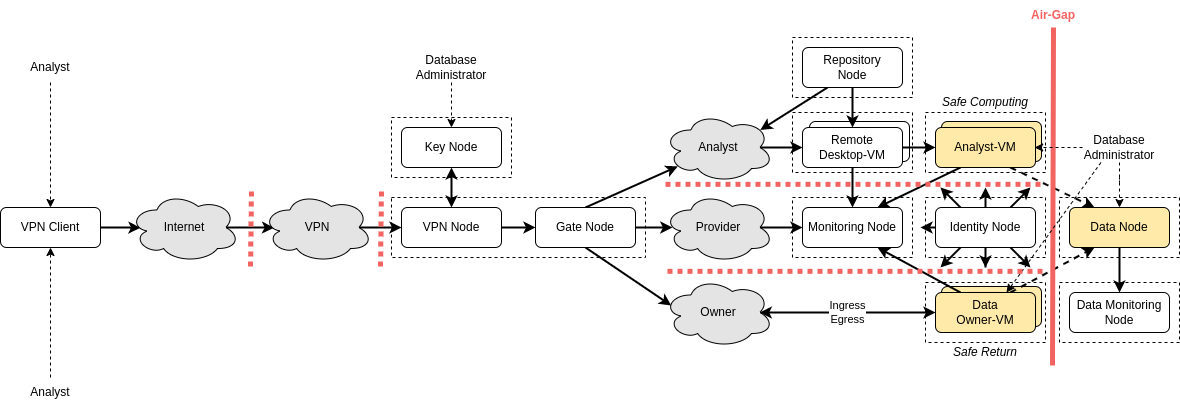
We define a set of VMs that form the core infrastructure (e.g. Data Owner-VMs , Remote Desktop-VMs, Analyst-VMs, and others) on a single Virtualization Host. By only providing remote desktop capabilities via a Remote Desktop-VM, custom policies like prevention of copy and paste can be enforced with low effort but come at a cost of maintaining a secure connection to the virtual network computing (VNC) Server. It handles the requests from the VNC Client. We deploy a fresh Remote Desktop-VM (running the VNC server) for each Analyst-VM, they form a functional tuple.
VPN¶
We encrypt the data stream using AES with keys of 128 bit length. A compromise of this key or the cipher can have fatal outcomes for our system, therefore we further isolate the remote desktop data stream using virtual private network (VPN) capabilities that creates a second encryption hull with different cipher.
Disks¶
The storage of all VMs in the infrastructure is encrypted using a securely generated key of minimum 4096 bits length that is further encrypted using a compound passphrase that resides only segmented on two separate Key Server machines. We achieve this by halving the passphrase and echoing it after successful authentication through secure shell to the Key Servers. The encryption key after decryption (using the passphrase) only resides within the random access memory (RAM) of the Virtualization Host. Further, the storage region of each VM is reserved during creation and zero-ed before initializing the encrypted virtual disk (see Key Servers).
Regularly deployed and deleted virtual machines are Analyst-VMs and Data Owner-VMs, which come with standard tools installed. The former allows data uploads by the Data Owner (from where it is subsequently transferred to the Data Server), whereas the latter is equipped with selected data subsets via secure copy from the Data Server upon creation.
Organizational Measures¶
Similar to the holistic approach to Trusted Research Environments we argue that only technical enforcement is not enough to keep sensitive data confidential for a multitude of reasons: ( i) establishing awareness that certain operations require more conscious decisions than others and may have unintended consequences attached to it; (ii) accountability which enables a transparent communication of important processes in the system and making actors of the processes responsible for certain steps of the processes; (iii) legally binding terms of use to allow the processing of personal information, non-disclosure agreements, data access agreement, etc.
For the majority of the organizational measures, we require only that the Analysts involved know how to use their preferred data processing and analytics tools (which are provided on-demand on the Analyst-VM). Little to no additional training thus should be required in order to execute common data science tasks on the isolated VMs. Although the secure data infrastructure is designed to automate as much of the processes as possible, a few steps require human intervention and are not suitable for automation.
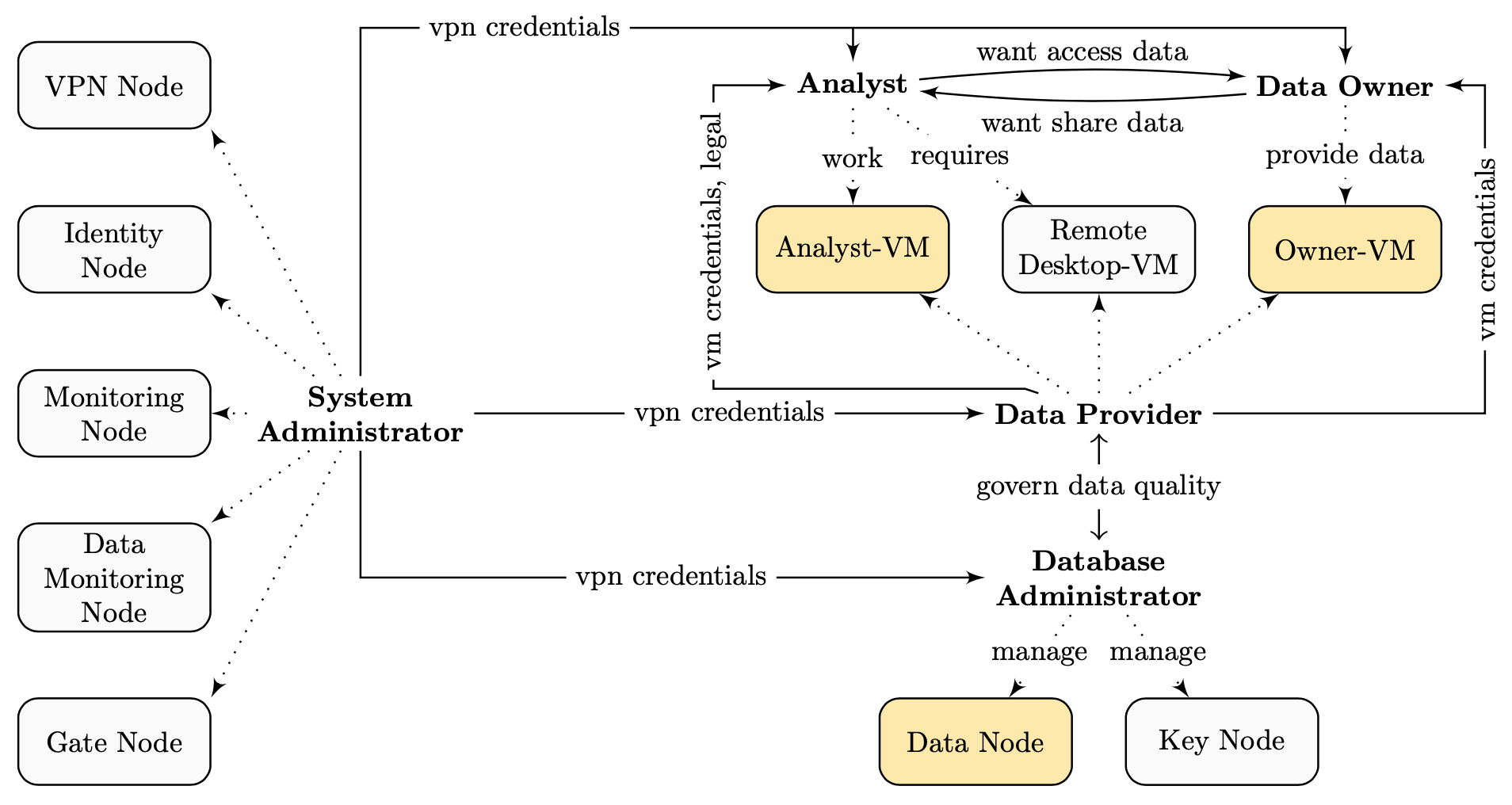
In the case of the isolated VMs, we want to create an air lock capability that strips as much communication functionality away from the virtual machine as possible but still maintain the ability to interact with it. With this draconian measures, we want to preserve the control over the data for the Data Owner. We do this by both technical (access only via Remote Desktop-VM from a dedicated machine) and Ð in context of this section Ð from an organizational perspective in form of legally binding terms of use and white-listing only components that have been audited.
Outsourcing of parts of a secure data infrastructure requires security design and engineering as well as contractual agreements with the third-party provider to minimize the risk of a data security breach. Although our approach does not recommend outsourcing of parts of the secure data infrastructure, it provides an automated base implementation that can be extended to be able to achieve this.
Core Infrastructure¶
The Virtualization Host is the physical hardware computing unit that provides the necessary resources for the virtualized components, specifically the five core infrastructure VMs plus dedicated, temporary VMs for data delivery by Data Owners and checking safe returns or result exports, and both a Remote Desktop-VM and Analyst-VM combination temporarily per task per Analyst. It is generally recommended to use specialized server hardware for this, but the set-up works with commodity hardware as well as long as the physical specifications support the required core infrastructure VMs, as well as the two Key Servers, as depicted below.
VPN Node¶
It is the endpoint for the analyst and data owner to establish a connection to the secure data infrastructure. We run a
standard OpenVPN Access Server implementation with the recommended
AES-256-CBC cipher without compression on UDP port 1194, that is installed automatically by the set-up playbook.
After the set-up completes, the system administrator and database administrator automatically receive a OpenVPN profile
(/home/sysadmin/sysadmin.ovpn and /root/dbadmin.ovpn) that allows them to connect to the VPN node. It is used as a
jump node by the system administrator via direct SSH connection. The database administrator has no SSH connection
capabilities.
OpenVPN profile creation
The playbooks handles not only the OpenVPN profile creation, but also the user-specific firewall rules, identitiy
generation and gate firewall rules. A manual call of the /usr/local/sbin/vpnadd script may not work.
When creating a user, the create-user.yml playbook creates a new profile for each user. The client-specific firewall
rules are managed by the playbook too. To revoke access to the VPN Node, currently, the OpenVPN profile needs to be
revoked manually on the VPN Node by the system administrator:
/usr/local/sbin/vpnrm username
Gate Node¶
Gate Server is the virtualized firewall component that manages the traffic between the different sub nets on the Virtualization Host.
The service allows to filter packets based on chains. To the basic three chains (INPUT,FORWARD,OUTPUT) we only add five additional chains during the initial set-up, that group the firewall rules for the secure data infrastructure:
- CORE chain, allows every component to access the installer.
- TOWORLD chain manages traffic that can establish connections through the open Internet, e.g. to approved license servers.
- VPN2DOVM chain manages connections from the VPN Server to a specific Data Owner-VM for a given Data Owner. Rules in this chain are automatically added and removed by the system through the Installer component.
- VNC2AVM chain manages the traffic from a specific Remote Desktop-VM to the associated Analyst-VM.
- VPN2VNC chain manages traffic from the VPN Server to the VNC instances on the Remote Desktop-VMs.
Identity Node¶
We do the installation with integrated DNS, with an integrated CA as the root CA
Monitoring Node¶
Logging Server is virtualized and runs the rsyslog end point which stores all events that are occurring in the secure data infrastructure. All monitoring activity is collected here and saved in audit trails.
This component should (ideally) operate using a hardware-protected write-once storage system, and have a separated access control, but is virtualized in the reference implementation set-up to provide a self-contained starting point.
The Logging Server collects logs from the core VMs, Analyst-VMs and Data Owner-VMs through TCP (port 514) in the provider network.
Data Owner-VM¶
Data Owner-VMs are temporary VMs created for the submission of Data Ingress by a Data Owner into the trusted infrastructure. Upon completion of the upload the data is shifted to the Data Server after which this VM can be deleted. Alternatively it may be used for "safe returns" (in terms of Trusted Research Environments) and data- or result exports as both processes may require clearing from the Data Owner.
A Data Owner-VM is, like a core VM, created through a kickstart install and the network file storage of
the Installer Server. However, the kickstart file is templated from the owner_ks.cfg.
The script replaces some placeholder variables with the correct values from the database of
the Installer Server.
- MACHINE_NAME
- OWNER_MAC
- DEFAULT_MAC
- PROVIDER_MAC
- USER_NAME
- USER_PASSWORD
- SSH_KEY
By default, the Data Owner-VM has 2 vCPU cores assigned and 4GB RAM assigned with a 10GB root partition and 10GB export partition. The Data Owner receives a notification 93 days after creation to either submit an extend form or for immediate deletion. By default, the Data Owner-VM gets deleted 100 days after creation. This is done through cron jobs.
Analyst-VM¶
Analyst-VMs are temporary VMs created individually for each analysis or data processing task. Upon creation with a zero-ed storage region they are equipped with a copy of the data subset and the tools required by the Analyst. Connections are solely possible to the corresponding Remote Desktop-VM and to verified license servers when required by specific tools, as well as for transferring result data to the associated Data Owner-VM for safe return and export.
An Analyst-VM is, like a core VM, created through a kickstart install and the network file storage of
the Installer Server. However, the kickstart file is templated from the analyst_ks.cfg
. The script replaces some placeholder variables with the correct values from the database of
the Installer Server.
- MACHINE_NAME
- ANALYST_MAC
- DEFAULT_MAC
- PROVIDER_MAC
- USER_NAME
- USER_PASSWORD
- SSH_KEY
By default, the Analyst-VM has 2 vCPU cores assigned and 4GB RAM assigned with a 10GB root partition and 10GB export partition. The Analyst receives a notification 93 days after creation to either submit an extend form or for immediate deletion. By default, the Analyst-VM gets deleted 100 days after creation. This is done through cron jobs.
Remote Desktop-VM¶
Remote Desktop-VMs are temporary VMs created individually for each Analyst-VM. We use TigerVNC as software implementation that runs inside the Remote Desktop-VM as a process.
The Remote Desktop-VM runs an instance of TigerVNC Server and is accessible through port 5900 by default. Note that no user account is created for this Remote Desktop-VM and the Analyst does not receive SSH credentials.
Data Node¶
Data Server is the virtualized central storage that holds sensitive data and can be isolated to a level that only a System Administrator role is able to access the server for maintenance, but not to make changes to the PostgreSQL database server running on it.
The PostgreSQL 10 database implements the RDA recommendations for dynamic data citation via temporal tables. It also supports PL/Python.
The Database Administrator is responsible for extracting subsets of sensitive data to the respective Analyst-VM. Upon completion and granted export request, the Database Administrator can extract artifacts to a Data Owner-VM.
Data Monitoring Node¶
tbd
Data Owner-VM¶
By default, the Data Owner-VM has software installed to allow data ingest.
- MariaDB 10.5
- LibreOffice Writer, Calc, Impress and Base
Key Node¶
Reference implementation
In the reference implementation we do not use a Key Node. Instead, we use the built-in encryption scheme of the OpenStack module Barbican that allows the System Administrator to deposit the encryption key on the dedicated key manager.
A Key Server is a physical server (not a VM on the Virtualization Host and not installed on the Virtualization Host) that is responsible for storing a part of the compound encryption key for the virtual disks of all VMs.
By default there are two key servers required that each hold 4096 bit part encryption key, therefore all disks are encrypted with a 8192 bit encryption key.
Only the Virtualization Host is authorized to view the part encryption keys. The mechanism works as follows: the Virtualization Host authenticates against both Key Servers with its SSH public key. Then, the part encryption key is echoed and the connection is terminated. More simplified it is just:
part1=$(ssh root@keys01)
part2=$(ssh root@keys02)
key="${part1}${part2}"