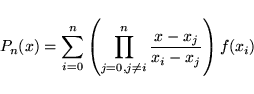Music comes in a variety of file formats such as MP3, WAV, AU, etc., all of which basically store the sound information in the form of pulse code modulation (PCM) using a very high sampling rate of 44.1 KHz. The analog sound signal is thus represented by 44.100 16 bit integer numbers per second, which are interpreted by media players to reproduce the sound signal. To be able to compute similarity scores between musical tunes, a feature vector representation of the various pieces of music needs to be created, which can further be analyzed by the SOM. Figure 1 provides an overview of the system architecture.
Starting with any popular music file format, most media players, such as the public domain X Multimedia System (XMMS) are capable of splitting this data stream into several frequency bands. Using the XMMS the signal is split into 256 frequency bands, with approximately one sample value every 20 to 25 ms each. Since not all frequency bands are necessary for evaluating sound similarity and in order to reduce the amount of data to be processed, a subset of 17 frequency bands (i.e. every 15th frequency band) is selected for further analysis, covering the whole spectrum available. In order to capture musical variations of a tune, the music stream is split into sections of 5 seconds length, which are further treated as the single musical entities to be analyzed. While basically all 5-second sequences could be used for further analysis, or even overlapping segments might be chosen, experimental results have shown that appropriate clustering results can be obtained by the SOM using only a subset of all available segments. Especially segments at the beginning as well as at the end of a specific piece of music can be eliminated to ignore fade-in and fade-out effects. Specifically, our results show that choosing every second to third segment, i.e. a 5-second interval every 10 to 15 seconds, provides sufficient quality of data analysis.
The intervals between the frequency snapshots provided by the player varies with the system load and can thus not be guaranteed to occur at specified time intervals.
We thus have a set of amplitude / timestamp values about every 20 to 25 ms in each of the 17 selected frequency bands.
In order to obtain equi-distant data points, a Lagrange interpolation is performed on these values as provided in Expression 1, where ![]() represents the amplitude of the sample point at time stamp
represents the amplitude of the sample point at time stamp ![]() the data points for up to
the data points for up to ![]() sample points.
sample points.
As a result of this transformation we now have equi-distant data samples in each frequency band.The resulting function can be approximated by a linear combination of sinus and cosines waves with different frequencies. We can thus obtain a closed representation for each frequency band by performing a Fast Fourier Transformation (FFT), resulting in a set of 256 coefficients for the respective sinus and cosines parts. Combining the 256 coefficients for the 17 frequency bands results in a 4352-dimensional vector representing a 5-seconds segment of music. These feature vectors are further used for training a SOM.
The Self-Organizing Map [5] is one of the
most prominent artificial neural network models adhering to the
unsupervised learning paradigm.
It provides a mapping from a high-dimensional input space to a usually two-dimensional output space while preserving topological relations as faithfully as possible.
Input signals ![]() are presented to the map, consisting of a grid of units with
are presented to the map, consisting of a grid of units with ![]() -dimensional weight vectors, in random order.
An activation function based on some metric (e.g. the Euclidean Distance) is used to determine the winning unit (the `winner').
In the next step the weight vector of the winner as well as the weight vectors of the neighboring units are modified following some learning rate in order to represent the presented input signal more closely.
As a results, after the training process, similar input patterns are mapped onto neighboring units of the Self-Organizing Map.
The feature vectors representing music segments can be thought of data points in a 4352-dimensional space, with similar pieces of music, i.e. segments exhibiting similar frequency spectra and thus similar FFT coefficients, being located close to each other.
Using the SOM to cluster these feature vectors, we may expect similar music segments to be located close to each other in the resulting map display.
-dimensional weight vectors, in random order.
An activation function based on some metric (e.g. the Euclidean Distance) is used to determine the winning unit (the `winner').
In the next step the weight vector of the winner as well as the weight vectors of the neighboring units are modified following some learning rate in order to represent the presented input signal more closely.
As a results, after the training process, similar input patterns are mapped onto neighboring units of the Self-Organizing Map.
The feature vectors representing music segments can be thought of data points in a 4352-dimensional space, with similar pieces of music, i.e. segments exhibiting similar frequency spectra and thus similar FFT coefficients, being located close to each other.
Using the SOM to cluster these feature vectors, we may expect similar music segments to be located close to each other in the resulting map display.
Using the resulting segment SOM, the various segments are scattered across the map according to their mutual similarity.
This allows, for example, pieces of music touching on different musical genres, to be located in two or more different clusters, whereas rather homogeneous pieces of music are usually located within one rather confined cluster on the map.
While this already provides a very intuitive interface to a musical collection, a second clustering may be built on top of the segment clustering to obtain a grouping of pieces of music according to their overall characteristics.
To obtain such a clustering, we use the mapping of the segments representing a single piece of music to obtain an overall clustering.
We thus create a feature vector representation for each piece of music using the location of its segments as descriptive attributes.
Given an ![]() SOM we create an
SOM we create an ![]() dimensional weight vector, where the attributes are the (coordinates of) the units of the segment SOM.
Each vector attribute represents the number of segments of a particular piece of music mapped onto the respective unit in the SOM.
For example, given a piece of music that has 3 segments mapped onto unit
dimensional weight vector, where the attributes are the (coordinates of) the units of the segment SOM.
Each vector attribute represents the number of segments of a particular piece of music mapped onto the respective unit in the SOM.
For example, given a piece of music that has 3 segments mapped onto unit ![]() in the upper right corner of the map, and 2 segments on the neighboring unit
in the upper right corner of the map, and 2 segments on the neighboring unit ![]() , the first two attributes of the song's feature vector are basically set to the according values
, the first two attributes of the song's feature vector are basically set to the according values
![]() , with subsequent norming to unit length to make up for length differences of songs.
Training a second SOM using these feature vectors we obtain a clustering where each piece of music is mapped onto one single location on the resulting map, with similar pieces of music being mapped close to each other.
, with subsequent norming to unit length to make up for length differences of songs.
Training a second SOM using these feature vectors we obtain a clustering where each piece of music is mapped onto one single location on the resulting map, with similar pieces of music being mapped close to each other.