 Department of Software Technology
Department of Software Technology
Vienna University of Technology
The SOMLib Digital Library - Experiments - CIA World Factbook 1990
Overview
This is the 1990 edition of the CIA World Factbook, describing various regions of the world in terms of their geographical, social, political, demographic etc. features.
Please note, that for our experiments we used the 1990 edition, i.e. a description of the world based on the situation before the 'fall' of the communist hemisphere.
It consists of 246 documents, or about 2.080 KB of plain ASCII text
On this page:
- Data
- Textrepresentation
- Trained Self-Organizing Maps (not interactive)
- Hierarchical Self-Organizing Maps (not interactive)
- Integration of Distributed Self-Organizing Maps (not interactive)
- GHSOM - Growing Hierarchical Self-Organizing Map (interactive exploration)
Data
The CIA World Factbook of 1990 consits of 246 documents, or about 2.080 KB of plain ASCII text.
Text Representation
The list below presents some of the vector representations created using various degrees of pruning the vector and different ways of word stemming methods, resulting in vector representations of different dimensionality.
Parsing the files results in a pruned template vector of about 800 - 1500 words.
Trained Self-Organizing Maps
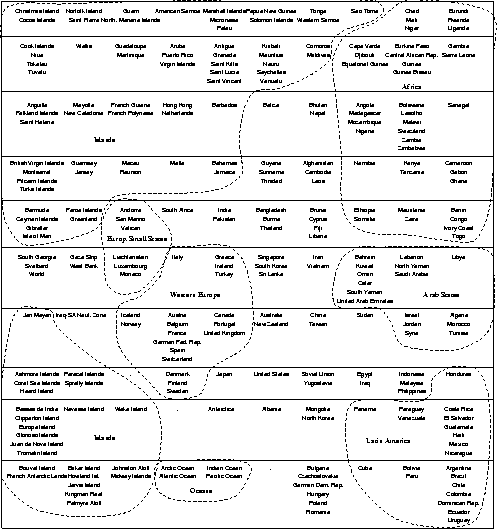
Based on the document description as outlined above, we trained a self-organizing map to represent the contents of the
document archive. Below we provide a graphical representation of the training result. For ease of identifying the various rows of units in
the graphical representation, we separated these rows by horizontal lines. Each unit is either marked by a number of countries (or
regions) or by a dot. The name of a country appears if this unit serves as the winner for that particular country (or more precisely for
the input vector representing that country). A dot appears if the unit is never selected as winner for any document.
The self-organizing map was quite successful in arranging the various input data according to their mutual
similarity. It should be obvious that in general countries belonging to similar geographical regions are rather similar with respect to
the different categories described in the CIA World Factbook. These geographical regions can be found in the two-dimensional map
display as well. In order to ease the interpretation of the self-organizing map's training result, we have marked several regions
manually. For example, the area on the left hand side of the map is allocated for documents describing various islands. We should
note, that the CIA World Factbook contains a large number of descriptions of islands. It is interesting to note, that the description of
the oceans can be found in a map region neighboring the area of islands.
In the lower center of the map we find the European countries. The cluster representing these countries is further decomposed into a
cluster of small countries, e.g. San Marino and Liechtenstein, a cluster of Western European countries, and finally a cluster of Eastern
European countries. The latter cluster is represented by a single unit in the last row of the output space. This unit has as neighbors
other countries that are usually attributed as belonging to the Communist hemisphere, e.g. Cuba, North Korea, Albania, and Soviet
Union. At this point it is important to recall that our document archive is the 1990 edition of the CIA World Factbook. Thus, the
descriptions refer to a time before the ``fall'' of the Communist hemisphere.
Other clusters of interest are the region containing countries from Latin America (lower right of the map), the cluster containing Arab
countries (middle right of the map), or the cluster of African countries (upper right of the map).
A different flat SOM of the WFB data was produced using the GHSOM - the Growing Hierarchical Self-Organizing Map,
with parameters set in a way that no hierarchical expansion was created. The resulting map is available for interactive browsing in the GHSOM Section further down this page.
Overall, the representation of the document space is highly successful in that similar documents are located close to one another.
Thus, it is easy to find an orientation in this document space.
Trained Self-Organizing Maps - Hierarchical SOMs
In the previous section we have described the results from using self-organizing maps with the data of the CIA World Factbook. The
major shortcoming of this neural network model is that the various documents are represented within only one two-dimensional
output space making it difficult to identify cluster boundaries without profound insight into the underlying document collection.
For the experiment presented thereafter we used a setup of the hierarchical feature map using four layers. The respective maps have
the following dimensions: 3x3 on the first layer, 4x4 on the second layer, and 3x3 on the third and fourth layer. This setup has been determined empirically.
In the remainder of this discussion we will just present the branch of the hierarchical feature map that contains what we called
economically developed countries on unit (1/2) in the middle right area of the top-level map. The other branches, however, are formed quite similarly.
Next, we show the arrangement of the second layer within the branch of economically developed countries. In this map, the
various countries are separated roughly according to either their geographic location or their political system. The clusters are
symbolized by using different shades of grey.
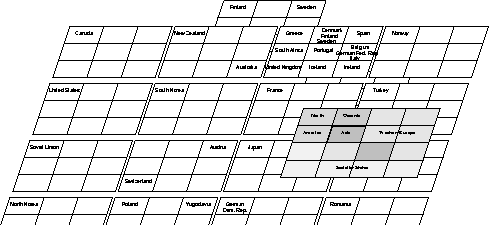
Finally, we present the full-blown branch of economically developed countries. In this case it is straight-forward to identify the
various cluster boundaries in that each cluster is represented by an individual self-organizing map. Higher level similarities are shown
in higher levels of the hierarchical feature map.
Integration of Distributed Self-Organizing Maps
For creating a number of first level SOMs the whole set of 245 documents was randomly split into 5 parts with each set comprising
50 documents, i.e. 5 documents are represented twice in different sets. Next, we independently trained 5 maps consisting of
nodes using these testsets. Each field in the maps represents
a node labeled with the names of the countries for which it is the best-matching representative, i.e. the winner. Units that were not
winner for any country appear as empty fields.
Each of these 5 maps represents in itself a topologically ordered mapping of the corresponding documents, which means that
countries considered similar to each other in terms of the facts given in the country description of the CIA Worldfactbook, are located
on the same node or close to each other. In the lower left corner of the first map, for example, we find a number of nodes
representing south american countries, which are followed by an european and developed countries area to the right. A cluster of
asian and african countries is situated above the south american cluster. Another interesting cluster in the upper middle of the first
map is represented by the arctic and antarctic oceans, followed by the antarctic continent and a number of islands. Another european
cluster can be found in the upper left part of the map on the right hand side.
Similar clusters may be found in all the other
maps, e.g. clusters of eastern european countries, countries of the arabic hemisphere. Note, however, that the clustering provided by
the mapping does not necessarily represent a geographical structuring of regions. Rather, the countries are organized on the map
according to their overall similarity based on the descriptions in the CIA Worldfactbook.
- Subset 1
- Subset 2
- Subset 3
- Subset 4
- Subset 5
In a second step, these 5 maps are integrated into one single SOM consisting of 7x7 units to represent the whole document
collection. Thus we obtain a mapping of all nodes of the 5 lower level maps onto the nodes of the higher level SOM.
The idea behind
this approach is based on the fact, that nodes in the various lower level SOMs representing similar documents (e.g. the nodes
representing oceans which are distributed across 3 lower level maps in our experimental setup) should be mapped onto one node in
the higher level SOM, i.e. we should expect one cluster for every region described in the document collection.
- Integrating Map of the World
Note, that the main clusters are clearly visible from the map representation due to the
accumulation of country descriptions on the cluster center nodes, with the nodes of the lower-level maps being mapped according to
a higher level of abstraction. Thus we find a cluster of african countries in the upper left part of the map, with its center on the
second node of the first row, being followed by a node representing south american countries in the middle of the first row. In the
upper right corner of the map we find a node representing western european and developed countries, followed again by a node
representing the former communist hemisphere below. Mind, that the documents used in these examples were taken from the 1990
edition of the CIA Worldfactbook, prior to the `fall' of the communist hemisphere.
We further find several clusters of islands as well as a single node representing the oceans mentioned before, situated in the lower
right part of the map. Please note that the countries that were present in the testbed twice (Austria, Comoros, Iceland, Japan and
Mozambique) are now all mapped onto identical nodes. Generally, the nodes in the various maps representing highly similar or
identical information, are now mapped onto the same area in the higher level representation of the text collection. Thus we find the
higher level map to form an orderly mapping of all the input data used for training the single lower-order maps, with these maps
now being integrated at a higher level of abstraction.
GHSOM - Growing hierarchical Self-Organizing Map
Below we provide some of the results of our experiments training the GHSOM model on the CIA World Factbook text
collection describing countries and regions of the world by the geography, climate, economy, population, political
system etc.
-
Flat Hierarchy GHSOM of the CIA World Factbook.
The parameter t1 was set such that at each layer of the GHSOM
hierarchy the map has to represent the data from the
higher-layer unit that it originates from at a significantly
larger degree of detail.
This results in a rather flat hierarchy.
-
Deep Hierarchy GHSOM of the CIA World Factbook.
The parameter t1 was set to a smaller value, such that the new layer in the hierarchy has to represent the
data at a more detailedlevel, but less so than with the flat GHSOM example. This results in a rather deep
hierarchy of smaller maps, which is favourable for large datasets where the various clusters are better separated.
-
Flat GHSOM of the CIA World Factbook.
The parameter t1 was set such that at already at the first layer of the GHSOM the map grew large enough to
represent the data at a granularity above threshold t2.
Thus, none of the units was expaned at a second layer, leaving us with one small map of the entire CIA World
Factbook.
In this case the GHSOM resembles the conventional Growing Grid SOM.
Up to the SOMLib Digital Library Homepage
Comments: rauber@ifs.tuwien.ac.at
{kind=link}
{kind=link}
{kind=link}
{kind=link}