Vienna University of Technology
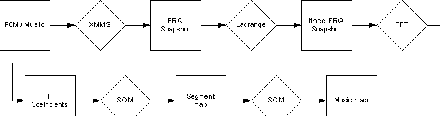
SOMeJB Prototype 1: SOM-enhanced JukeBox System: feature extraction, conversion, 1st- and 2nd-level SOM training.
Starting with any popular music file format, most media players, such as the open source X Multimedia System (XMMS) are capable of splitting this data stream into several frequency bands. Using XMMS, the signal is split into 256 frequency bands, with approximately one sample value every 20 to 25 ms each. Since not all frequency bands are necessary for evaluating sound similarity, and in order to reduce the amount of data to be processed, a subset of 17 frequency bands (i.e. every 15th frequency band) is selected for further analysis, covering the whole spectrum available. In order to capture musical variations of a tune, the music stream is split into sections of 5 seconds length, which are further treated as the single musical entities to be analyzed. While basically all 5-second sequences could be used for further analysis, or even overlapping segments might be chosen, experimental results have shown that appropriate clustering results can be obtained by the SOM using only a subset of all available segments. Especially segments at the beginning as well as at the end of a specific piece of music can be eliminated to ignore fade-in and fade-out effects. Furthermore, our results show that choosing every second to third segment, i.e. a 5-second interval every 10 to 15 seconds, provides sufficient quality of data analysis.
The intervals between the frequency snapshots provided by the player varies with the system load and can thus not be guaranteed to occur at specified time intervals. We thus have a set of amplitude/timestamp values about every 20 to 25 ms in each of the 17 selected frequency bands. In order to obtain equi-distant data points, a Lagrange interpolation is performed on these values.
As a result of this transformation we now have equi-distant data samples in each frequency band. The resulting function can be approximated by a linear combination of sine and cosine waves with different frequencies. We can thus obtain a closed representation for each frequency band by performing a Fast Fourier Transformation (FFT), resulting in a set of 256 coefficients for the respective sine and cosine parts. Combining the 256 coefficients for the 17 frequency bands results in a 4352-dimensional vector representing a 5-second segment of music. These feature vectors are further used for training a Self-Organizing Map.
The training process of self-organizing maps may be described in terms
of input pattern presentation and weight vector adaptation.
Each training iteration t starts with the random selection of one
input pattern x(t).
This input pattern is presented to the self-organizing map and each
unit determines its activation.
Usually, the Euclidean distance between weight vector and input pattern
is used to calculate a unit's activation.
The unit with the lowest activation is referred to as the winner, c,
of the training iteration, i.e.
![]() .
Finally, the weight vector of the winner as well as the weight vectors
of selected units in the vicinity of the winner are adapted.
This adaptation is implemented as a gradual reduction of the
component-wise difference between input pattern and weight vector,
i.e.
.
Finally, the weight vector of the winner as well as the weight vectors
of selected units in the vicinity of the winner are adapted.
This adaptation is implemented as a gradual reduction of the
component-wise difference between input pattern and weight vector,
i.e.
![]() .
Geometrically speaking, the weight vectors of the adapted units are
moved a bit towards the input pattern.
The amount of weight vector movement is guided by a so-called
learning rate, alpha,decreasing in time.
The number of units that are affected by adaptation is determined
by a so-called neighborhood function, hci.
This number of units also decreases in time.
This movement has as a consequence, that the Euclidean distance between
those vectors decreases and thus, the weight vectors become more
similar to the input pattern.
The respective unit is more likely to win at future presentations
of this input pattern.
The consequence of adapting not only the winner alone but also
a number of units in the neighborhood of the winner leads
to a spatial clustering of similar input patters in neighboring parts
of the self-organizing map.
Thus, similarities between input patterns that are present in the
n-dimensional input space are mirrored within the two-dimensional
output space of the self-organizing map.
The training process of the self-organizing map describes a topology
preserving mapping from a high-dimensional input space onto a
two-dimensional output space where patterns that are similar in terms
of the input space are mapped to geographically close locations in
the output space.
.
Geometrically speaking, the weight vectors of the adapted units are
moved a bit towards the input pattern.
The amount of weight vector movement is guided by a so-called
learning rate, alpha,decreasing in time.
The number of units that are affected by adaptation is determined
by a so-called neighborhood function, hci.
This number of units also decreases in time.
This movement has as a consequence, that the Euclidean distance between
those vectors decreases and thus, the weight vectors become more
similar to the input pattern.
The respective unit is more likely to win at future presentations
of this input pattern.
The consequence of adapting not only the winner alone but also
a number of units in the neighborhood of the winner leads
to a spatial clustering of similar input patters in neighboring parts
of the self-organizing map.
Thus, similarities between input patterns that are present in the
n-dimensional input space are mirrored within the two-dimensional
output space of the self-organizing map.
The training process of the self-organizing map describes a topology
preserving mapping from a high-dimensional input space onto a
two-dimensional output space where patterns that are similar in terms
of the input space are mapped to geographically close locations in
the output space.
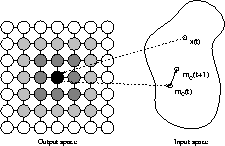
Consider Figure 1 for a graphical representation of self-organizing maps. The map consists of a square arrangement of 7x7 neural processing elements, i.e. units, shown as circles on the left hand side of the figure. The black circle indicates the unit that was selected as the winner for the presentation of input pattern x(t). The weight vector of the winner, mc(t), is moved towards the input pattern and thus, mc(t+1) is nearer to x(t) than was mc(t). Similar, yet less strong, adaptation is performed with a number of units in the vicinity of the winner. These units are marked as shaded circles in Figure 1. The degree of shading corresponds to the strength of adaptation. Thus, the weight vectors of units shown with a darker shading are moved closer to x than units shown with a lighter shading.
As a result of the training process, similar input data are mapped onto neighboring regions of the map. In the case of text document classification, documents on similar topics as indicated by their feature vector representations, are grouped accordingly. For examples of resulting document mappings, see below.
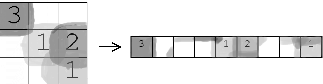
Creating 2nd level feature vectors based on segment distribution
Instead of directly using the number of segments mapped onto a specific unit as the attribute of the newly created input vector for a given piece of music, we may improve data representation by incorporating information about the similarity of a given segment with the weight vector of the unit it is mapped onto. As the weight vector serves as a cluster prototype, we can use the mapping distance between a segments feature vector and the unit's weight vector to give higher weights to segments that are very similar to the cluster centroid, whereas we may give lower weights to segments that are not mapped as well onto this unit. Furthermore, we may distribute the contribution of a segment being mapped onto a specific unit also across units in the neighborhood, utilizing the topology-preserving characteristics of the SOM. This allows for a more stable representation of the segments distribution across the segment map. A Gaussian centered at the winner can thus be used to model the contribution of each segment's location onto the neighboring units, and thus onto the attributes of the feature vector for the music SOM, as indicated by the shadings in the figure above.
We thus create a feature vector for each particular piece of music based on the distribution of its segments on the segment SOM. Training a second SOM using these feature vectors we obtain a clustering where each piece of music is mapped onto one single location on the resulting map, with similar pieces of music being mapped close to each other.