Vienna University of Technology
The training process of self-organizing maps may be described in terms
of input pattern presentation and weight vector adaptation.
Each training iteration t starts with the random selection of one
input pattern x(t).
This input pattern is presented to the self-organizing map and each
unit determines its activation.
Usually, the Euclidean distance between weight vector and input pattern
is used to calculate a unit's activation.
The unit with the lowest activation is referred to as the winner, c,
of the training iteration, i.e.
![]() .
Finally, the weight vector of the winner as well as the weight vectors
of selected units in the vicinity of the winner are adapted.
This adaptation is implemented as a gradual reduction of the
component-wise difference between input pattern and weight vector,
i.e.
.
Finally, the weight vector of the winner as well as the weight vectors
of selected units in the vicinity of the winner are adapted.
This adaptation is implemented as a gradual reduction of the
component-wise difference between input pattern and weight vector,
i.e.
![]() .
Geometrically speaking, the weight vectors of the adapted units are
moved a bit towards the input pattern.
The amount of weight vector movement is guided by a so-called
learning rate,
.
Geometrically speaking, the weight vectors of the adapted units are
moved a bit towards the input pattern.
The amount of weight vector movement is guided by a so-called
learning rate, ![]() ,
decreasing in time.
The number of units that are affected by adaptation is determined
by a so-called neighborhood function, hci.
This number of units also decreases in time.
This movement has as a consequence, that the Euclidean distance between
those vectors decreases and thus, the weight vectors become more
similar to the input pattern.
The respective unit is more likely to win at future presentations
of this input pattern.
The consequence of adapting not only the winner alone but also
a number of units in the neighborhood of the winner leads
to a spatial clustering of similar input patters in neighboring parts
of the self-organizing map.
Thus, similarities between input patterns that are present in the
n-dimensional input space are mirrored within the two-dimensional
output space of the self-organizing map.
The training process of the self-organizing map describes a topology
preserving mapping from a high-dimensional input space onto a
two-dimensional output space where patterns that are similar in terms
of the input space are mapped to geographically close locations in
the output space.
,
decreasing in time.
The number of units that are affected by adaptation is determined
by a so-called neighborhood function, hci.
This number of units also decreases in time.
This movement has as a consequence, that the Euclidean distance between
those vectors decreases and thus, the weight vectors become more
similar to the input pattern.
The respective unit is more likely to win at future presentations
of this input pattern.
The consequence of adapting not only the winner alone but also
a number of units in the neighborhood of the winner leads
to a spatial clustering of similar input patters in neighboring parts
of the self-organizing map.
Thus, similarities between input patterns that are present in the
n-dimensional input space are mirrored within the two-dimensional
output space of the self-organizing map.
The training process of the self-organizing map describes a topology
preserving mapping from a high-dimensional input space onto a
two-dimensional output space where patterns that are similar in terms
of the input space are mapped to geographically close locations in
the output space.
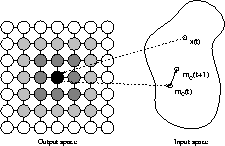
Consider Figure 1 for a graphical representation
of self-organizing maps.
The map consists of a square arrangement of
![]() neural processing
elements, i.e. units, shown as circles on the left hand side of the figure.
The black circle indicates the unit that was selected as the winner
for the presentation of input pattern x(t).
The weight vector of the winner, mc(t), is moved
towards the input pattern and thus, mc(t+1) is nearer to x(t) than
was mc(t).
Similar, yet less strong, adaptation is performed with a number of units
in the vicinity of the winner.
These units are marked as shaded circles in Figure 1.
The degree of shading corresponds to the strength of adaptation.
Thus, the weight vectors of units shown with a darker shading are moved
closer to x than units shown with a lighter shading.
neural processing
elements, i.e. units, shown as circles on the left hand side of the figure.
The black circle indicates the unit that was selected as the winner
for the presentation of input pattern x(t).
The weight vector of the winner, mc(t), is moved
towards the input pattern and thus, mc(t+1) is nearer to x(t) than
was mc(t).
Similar, yet less strong, adaptation is performed with a number of units
in the vicinity of the winner.
These units are marked as shaded circles in Figure 1.
The degree of shading corresponds to the strength of adaptation.
Thus, the weight vectors of units shown with a darker shading are moved
closer to x than units shown with a lighter shading.
As a result of the training process, similar input data are mapped onto neighboring regions of the map. In the case of text document classification, documents on similar topics as indicated by their feature vector representations, are grouped accordingly.
The starting point for the growth process is the overall deviation of
the input data as measured with the single-unit SOM at layer 0.
This unit is assigned a weight vector ![]() ,
,
![]() ,
computed as the average of all input data.
The deviation of the input data, i.e. the mean quantization error
of this single unit, is computed as given in Expression (1) with
,
computed as the average of all input data.
The deviation of the input data, i.e. the mean quantization error
of this single unit, is computed as given in Expression (1) with
![]() representing the number of input data
representing the number of input data ![]() .
We will refer to the mean quantization error of a unit as mqe
in lower case letters.
.
We will refer to the mean quantization error of a unit as mqe
in lower case letters.
After the computation of ![]() , training of the GHSOM starts
with its first layer SOM.
This first layer map initially consists of a rather small number of units,
e.g. a grid of
, training of the GHSOM starts
with its first layer SOM.
This first layer map initially consists of a rather small number of units,
e.g. a grid of ![]() units.
Each of these units
units.
Each of these units ![]() is assigned an
is assigned an ![]() -dimensional weight vector
-dimensional weight vector ![]() ,
,
![]() ,
, ![]() ,
which is initialized with random values.
It is important to note that the weight vectors have the same dimensionality
as the input patterns.
,
which is initialized with random values.
It is important to note that the weight vectors have the same dimensionality
as the input patterns.
The learning process of SOMs may be described as a competition among the units to represent the input patterns. The unit with the weight vector being closest to the presented input pattern in terms of the input space wins the competition. The weight vector of the winner as well as units in the vicinity of the winner are adapted in such a way as to resemble more closely the input pattern.
The degree of adaptation is guided by means of a learning-rate parameter
![]() , decreasing in time.
The number of units that are subject to adaptation also decreases in time
such that at the beginning of the learning process a large number of units around the winner is adapted, whereas towards the end only the winner is adapted.
These units are chosen by means of a neighborhood function
, decreasing in time.
The number of units that are subject to adaptation also decreases in time
such that at the beginning of the learning process a large number of units around the winner is adapted, whereas towards the end only the winner is adapted.
These units are chosen by means of a neighborhood function ![]() which is
based on the units' distances to the winner as measured in the
two-dimensional grid formed by the neural network.
In combining these principles of SOM training, we may
write the learning rule as given in Expression (2), where
which is
based on the units' distances to the winner as measured in the
two-dimensional grid formed by the neural network.
In combining these principles of SOM training, we may
write the learning rule as given in Expression (2), where ![]() represents the current input pattern, and
represents the current input pattern, and ![]() refers to the winner at
iteration
refers to the winner at
iteration ![]() .
.
In order to adapt the size of this first layer SOM, the
mean quantization error of the map is computed ever after a fixed
number ![]() of training iterations as given in Expression
(3).
In this formula,
of training iterations as given in Expression
(3).
In this formula, ![]() refers to the number of units
refers to the number of units ![]() contained in the
SOM
contained in the
SOM ![]() .
In analogy to Expression (1),
.
In analogy to Expression (1), ![]() is computed as the
average distance between weight vector
is computed as the
average distance between weight vector ![]() and the input patterns mapped
onto unit
and the input patterns mapped
onto unit ![]() .
We will refer to the mean quantization error of a map as MQE
in upper case letters.
.
We will refer to the mean quantization error of a map as MQE
in upper case letters.
The basic idea is that each layer of the GHSOM is responsible for explaining some portion of the
deviation of the input data as present in its preceding layer.
This is done by adding units to the SOMs on each
layer until a suitable size of the map is reached.
More precisely, the SOMs on each layer are allowed to
grow until the deviation present in the unit of its preceding layer
is reduced to at least a fixed percentage ![]() .
Obviously, the smaller the parameter
.
Obviously, the smaller the parameter ![]() is chosen the larger will be the
size of the emerging SOM.
Thus, as long as
is chosen the larger will be the
size of the emerging SOM.
Thus, as long as
![]() holds true for the first layer map
holds true for the first layer map ![]() , either a new row or a new
column of units is added to this SOM.
This insertion is performed neighboring the unit
, either a new row or a new
column of units is added to this SOM.
This insertion is performed neighboring the unit ![]() with the highest
mean quantization error,
with the highest
mean quantization error, ![]() ,
after
,
after ![]() training iterations.
We will refer to this unit as the error unit.
The distinction whether a new row or a new column is inserted is guided
by the location of the most dissimilar neighboring unit to the
error unit.
Similarity is measured in the input space.
Hence, we insert a new row or a new column depending on the position
of the neighbor with the most dissimilar weight vector.
The initialization of the weight vectors of the new units is simply
performed as the average of the weight vectors of the existing neighbors.
After the insertion, the learning-rate parameter
training iterations.
We will refer to this unit as the error unit.
The distinction whether a new row or a new column is inserted is guided
by the location of the most dissimilar neighboring unit to the
error unit.
Similarity is measured in the input space.
Hence, we insert a new row or a new column depending on the position
of the neighbor with the most dissimilar weight vector.
The initialization of the weight vectors of the new units is simply
performed as the average of the weight vectors of the existing neighbors.
After the insertion, the learning-rate parameter ![]() and the
neighborhood function
and the
neighborhood function ![]() are reset to their initial values and training
continues according to the standard training process of SOMs.
Note that we currently use the same value of the parameter
are reset to their initial values and training
continues according to the standard training process of SOMs.
Note that we currently use the same value of the parameter ![]() for each map in each layer of the GHSOM.
It might be subject to further research, however, to search for
alternative strategies, where layer or even map-dependent
quantization error reduction parameters are utilized.
for each map in each layer of the GHSOM.
It might be subject to further research, however, to search for
alternative strategies, where layer or even map-dependent
quantization error reduction parameters are utilized.
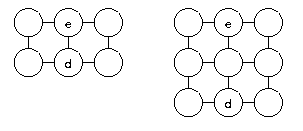
Consider the following figure for a graphical representation of the
insertion of units.
In this figure the architecture of the SOM prior to
insertion is shown on the left-hand side where we find a map of
![]() units with the error unit labeled by e and
its most dissimilar neighbor signified by d.
Since the most dissimilar neighbor belongs to another row within
the grid, a new row is inserted between units e and d.
The resulting architecture is shown on the right-hand side of the
figure as a map of now
units with the error unit labeled by e and
its most dissimilar neighbor signified by d.
Since the most dissimilar neighbor belongs to another row within
the grid, a new row is inserted between units e and d.
The resulting architecture is shown on the right-hand side of the
figure as a map of now ![]() units.
units.
As soon as the growth process of the first layer map is finished,
i.e.
![]() ,
the units of this
map are examined for expansion on the second layer.
In particular, those units that have a large
mean quantization error will add a new SOM
to the second layer of the GHSOM.
The selection of these units is based on the
mean quantization error of layer 0.
A parameter
,
the units of this
map are examined for expansion on the second layer.
In particular, those units that have a large
mean quantization error will add a new SOM
to the second layer of the GHSOM.
The selection of these units is based on the
mean quantization error of layer 0.
A parameter ![]() is used to describe the desired level of
granularity in input data discrimination in the final maps.
More precisely, each unit
is used to describe the desired level of
granularity in input data discrimination in the final maps.
More precisely, each unit ![]() fulfilling the criterion given in
Expression (4) will be subject to
hierarchical expansion.
fulfilling the criterion given in
Expression (4) will be subject to
hierarchical expansion.
The training process and unit insertion procedure now continues with these newly established SOMs. The major difference to the training process of the second layer map is that now only that fraction of the input data is selected for training which is represented by the corresponding first layer unit. The strategy for row or column insertion as well as the termination criterion is essentially the same as used for the first layer map. The same procedure is applied for any subsequent layers of the GHSOM.
The training process of the GHSOM is
terminated when no more units require further expansion.
Note that this training process does not necessarily lead to a balanced
hierarchy, i.e. a hierarchy with equal depth in each branch.
Rather, the specific requirements of the input data is mirrored in that
clusters might exist that are more structured than others and thus need
deeper branching.
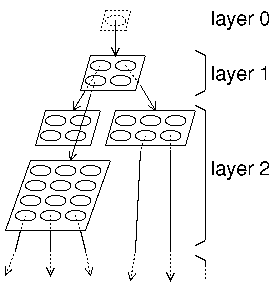
Consider Figure 2 for a graphical representation of a
trained GHSOM.
In particular, the neural network depicted in this figure consists
of a single-unit SOM at layer 0, a SOM of ![]() units
in layer 1, three SOMs in layer 2, i.e. one for each unit in the
layer 1 map.
Note that each of these maps might have a different number and different
arrangements of units as shown in the figure.
Finally, we have several SOMs in layer 3 which were expanded
from one of the layer 2 units, just indicated by dotted arrows.
units
in layer 1, three SOMs in layer 2, i.e. one for each unit in the
layer 1 map.
Note that each of these maps might have a different number and different
arrangements of units as shown in the figure.
Finally, we have several SOMs in layer 3 which were expanded
from one of the layer 2 units, just indicated by dotted arrows.
To summarize, the growth process of the GHSOM is guided by two parameters
![]() and
and ![]() .
The parameter
.
The parameter ![]() specifies the desired quality of input data
representation at the end of the training process.
Each unit
specifies the desired quality of input data
representation at the end of the training process.
Each unit ![]() with
with
![]() will be
expanded, i.e. a map is added to the next layer of the hierarchy, in order
to explain the input data in more detail.
Contrary to that, the parameter
will be
expanded, i.e. a map is added to the next layer of the hierarchy, in order
to explain the input data in more detail.
Contrary to that, the parameter ![]() specifies the desired level of
detail that is to be shown in a particular SOM.
In other words, new units are added to a SOM
until the MQE of the map is a certain fraction,
specifies the desired level of
detail that is to be shown in a particular SOM.
In other words, new units are added to a SOM
until the MQE of the map is a certain fraction, ![]() ,
of the mqe of its preceding unit.
Hence, the smaller
,
of the mqe of its preceding unit.
Hence, the smaller ![]() the larger will be the emerging maps.
Conversely, the larger
the larger will be the emerging maps.
Conversely, the larger ![]() the deeper will be the hierarchy.
the deeper will be the hierarchy.